What is TrOCR?
TrOCR (Transformer-based Optical Character Recognition) is an OCR model developed by Microsoft that uses Transformer architecture to recognize text from images.
Unlike traditional OCR systems that rely on multiple pipelines (text detection + recognition), TrOCR treats OCR as a sequence-to-sequence problem, similar to machine translation.
This allows it to achieve state-of-the-art performance on both:
- Handwritten text
- Printed documents
- Historical documents
- Medical notes
The model is built using Vision Transformer (ViT) + Transformer decoder, enabling it to understand images and generate text sequences.
How TrOCR Works
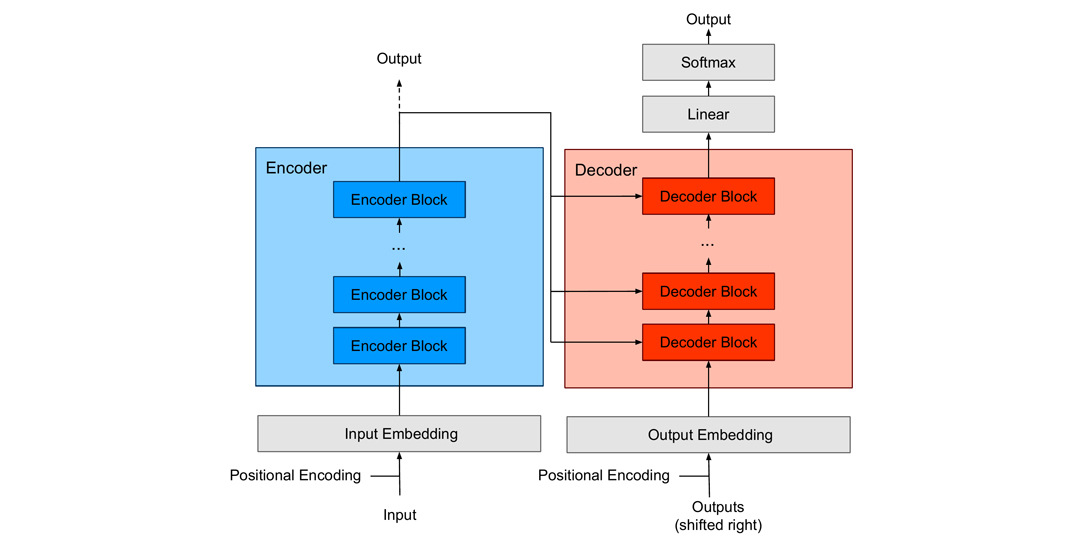

TrOCR uses an encoder-decoder transformer architecture.
1️⃣ Image Encoder
The input image is passed into a Vision Transformer (ViT) which extracts visual features from the document.
2️⃣ Feature Understanding
The encoder converts the image into contextual embeddings representing characters and patterns.
3️⃣ Text Generation
A Transformer decoder generates the corresponding text sequence.
This is similar to how translation models convert English → French, but here it converts:
Image → TextWhy TrOCR is Better Than Traditional OCR
| Feature | Traditional OCR | TrOCR |
|---|---|---|
| Architecture | Multi-stage pipeline | End-to-end Transformer |
| Handwriting recognition | Weak | Strong |
| Context understanding | Limited | Strong |
| Training | Rule-based + ML | Deep learning |
| Accuracy | Medium | Very high |
Because TrOCR uses context-aware transformers, it can understand messy handwriting better than classical OCR engines.
Pretrained TrOCR Models
Microsoft released several pretrained models.
| Model | Purpose |
|---|---|
trocr-base-printed |
Printed documents |
trocr-base-handwritten |
Handwritten text |
trocr-large-printed |
Higher accuracy printed OCR |
trocr-large-handwritten |
Best for handwriting |
These models are available through the Hugging Face model hub.
Example: Using TrOCR with Python
Here is a simple Python example using the transformers library.
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-handwritten")
model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-handwritten")
url = "https://example.com/handwritten.png"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(text)Output:
This is handwritten textReal-World Use Cases
TrOCR is widely used in many industries.
📄 Document Digitization
- Converting scanned documents into searchable text.
🏥 Medical Records
- Reading handwritten prescriptions
- Extracting clinical notes
🏛 Historical Document Preservation
- Digitizing centuries-old manuscripts.
🧾 Invoice & Form Processing
- Extracting structured data from forms.
Example: Medical Prescription OCR
In healthcare systems, doctors often write handwritten prescriptions, which are difficult for traditional OCR systems.
TrOCR can help extract text from:
- Doctor prescriptions
- Lab reports
- Medical notes
This enables building applications like:
- Prescription analyzers
- Digital health record systems
- AI medical assistants
Limitations of TrOCR
Despite its accuracy, TrOCR still has some challenges.
- Struggles with extremely messy handwriting
- Requires GPU for faster inference
- Needs fine-tuning for domain-specific data
For example, medical handwriting may require additional training with medical datasets.
Conclusion
TrOCR represents a major step forward in OCR technology by leveraging Transformer architectures.
Compared to traditional OCR engines, it offers:
- Better handwriting recognition
- Context-aware predictions
- End-to-end deep learning architecture
For developers building document AI systems, medical OCR tools, or automation pipelines, TrOCR is a powerful solution.