🧠 Introduction
The biggest bottleneck in scaling Large Language Models (LLMs) is no longer just compute — it's memory.
Recently, Google DeepMind introduced TurboQuant, a breakthrough technique that claims:
- ✅ Up to 6x reduction in KV cache memory
- ⚡ Faster inference speeds
- 🎯 Minimal accuracy loss
If validated at scale, this could significantly change how we design and deploy AI systems.
🔍 What is TurboQuant?
TurboQuant is a low-bit quantization technique focused specifically on compressing the KV cache (Key-Value cache) used in transformer-based models.
Instead of storing attention values in high precision:
- It compresses them into ultra-low-bit formats (~3-bit)
- Maintains near-original model performance
- Requires no retraining
👉 This makes it highly practical for real-world deployments.
🧠 Understanding the KV Cache Bottleneck
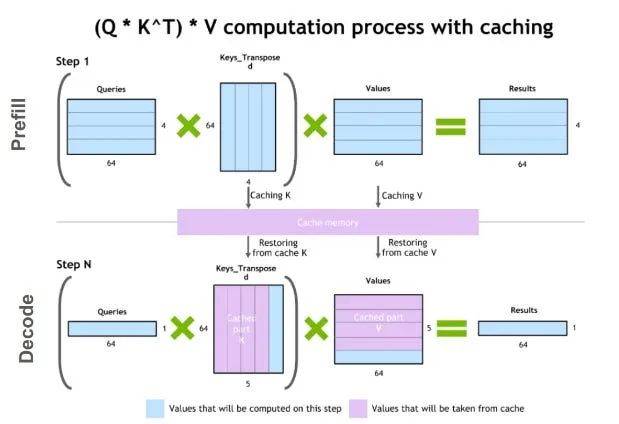
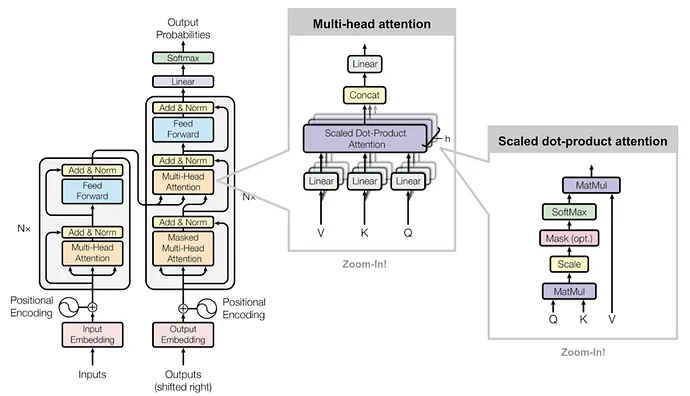
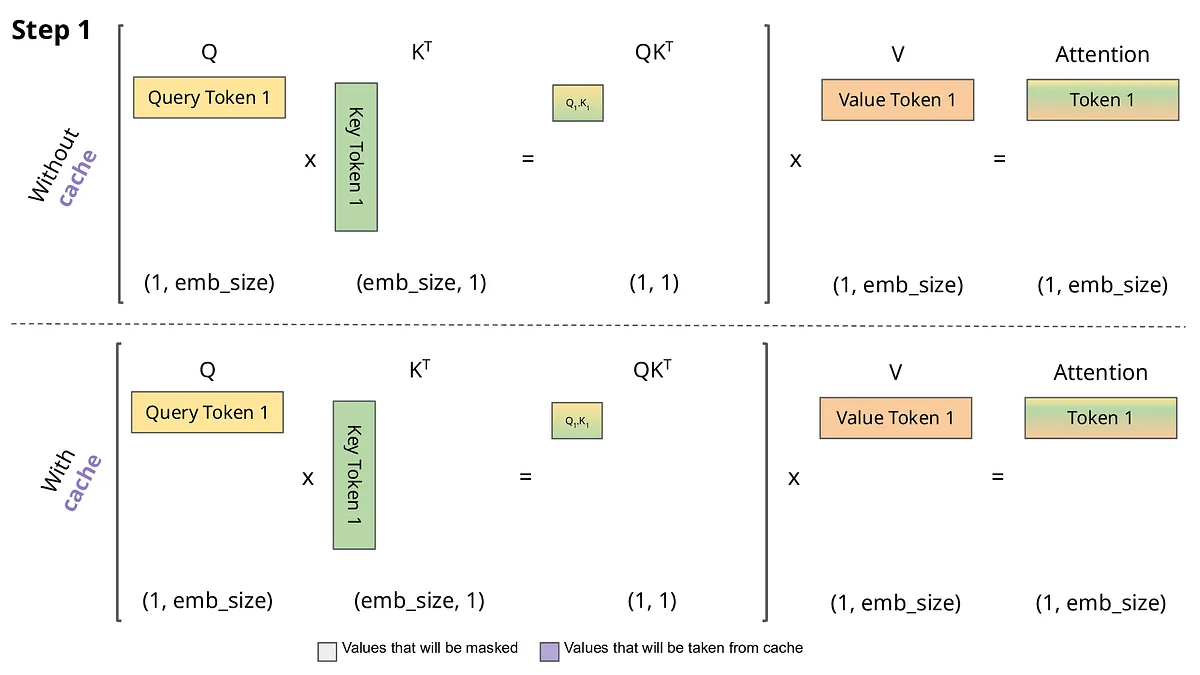
📌 What is KV Cache?
KV cache stores intermediate attention values during inference to speed up token generation.
⚠️ Why it’s a problem:
- Memory usage grows linearly with sequence length
- Consumes a large portion of GPU VRAM
- Limits long-context and multi-user systems
👉 In production systems like RAG or chat apps, this becomes a major scalability constraint.
⚡ Key Benefits of TurboQuant
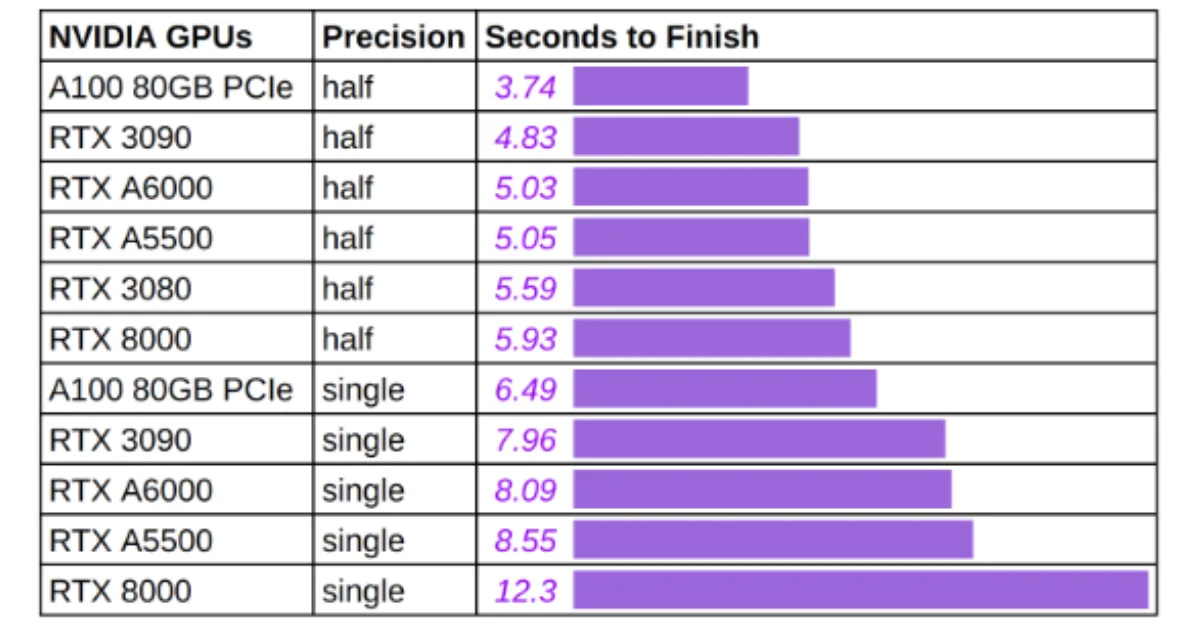
🚀 1. Massive Memory Reduction
- Up to 6x lower KV cache memory
- More users per GPU
- Better hardware utilization
⚡ 2. Faster Inference
- Reduced memory bandwidth usage
- Faster attention computation
- Up to 8x speed improvement (scenario dependent)
💰 3. Lower Infrastructure Cost
- Fewer GPUs required
- Reduced cloud cost
- Improved ROI for AI deployments
🧩 Real-World Impact
🔹 1. RAG (Retrieval-Augmented Generation)
- Larger context windows
- More documents processed per query
- Better answer quality
🔹 2. Multi-Tenant AI Systems
- Higher throughput per GPU
- Better scalability for SaaS AI platforms
🔹 3. Edge AI & Local Deployment
- Makes running LLMs feasible on smaller hardware
- Enables offline AI applications
⚖️ TurboQuant vs Traditional Quantization
| Feature | Traditional Quantization | TurboQuant |
|---|---|---|
| Focus | Model weights | KV cache |
| Retraining | Often required | Not required |
| Impact | Model size | Runtime memory |
| Use Case | Deployment optimization | Inference optimization |
⚠️ Limitations
- Focuses only on KV cache, not full model compression
- Performance gains depend on workload
- Still early — needs broader benchmarking
🔮 Future of LLM Optimization
TurboQuant highlights an important shift:
From “bigger models + bigger GPUs” To “smarter inference + efficient memory usage”
This aligns with trends like:
- Efficient transformers
- Sparse architectures
- Memory-aware optimizations
💡 Final Thoughts
TurboQuant may not be a new model — but it’s a critical infrastructure breakthrough.
If widely adopted, it could:
- Reduce AI serving costs significantly
- Enable longer context windows
- Improve scalability of real-time AI systems
👉 In short: Efficiency is becoming the new frontier in AI.
❓ FAQ (SEO Optimized)
What is Google TurboQuant?
TurboQuant is a KV cache compression technique developed by Google DeepMind that reduces memory usage and improves inference speed in LLMs.
How much memory does TurboQuant save?
It can reduce KV cache memory usage by up to 6x, depending on the model and workload.
Does TurboQuant reduce accuracy?
It is designed to maintain near-original accuracy with minimal degradation.
Does TurboQuant require retraining?
No, it works with existing models without retraining.
Where can TurboQuantTurboQuant be used?
It is useful in:
- RAG systems
- Chat applications
- Long-context AI models
- Multi-user AI platforms